本次阶段考核所需软件:分布式阶段考核2软件 - Cloudreve
密码:1234
需求1:创建一台新的虚拟机
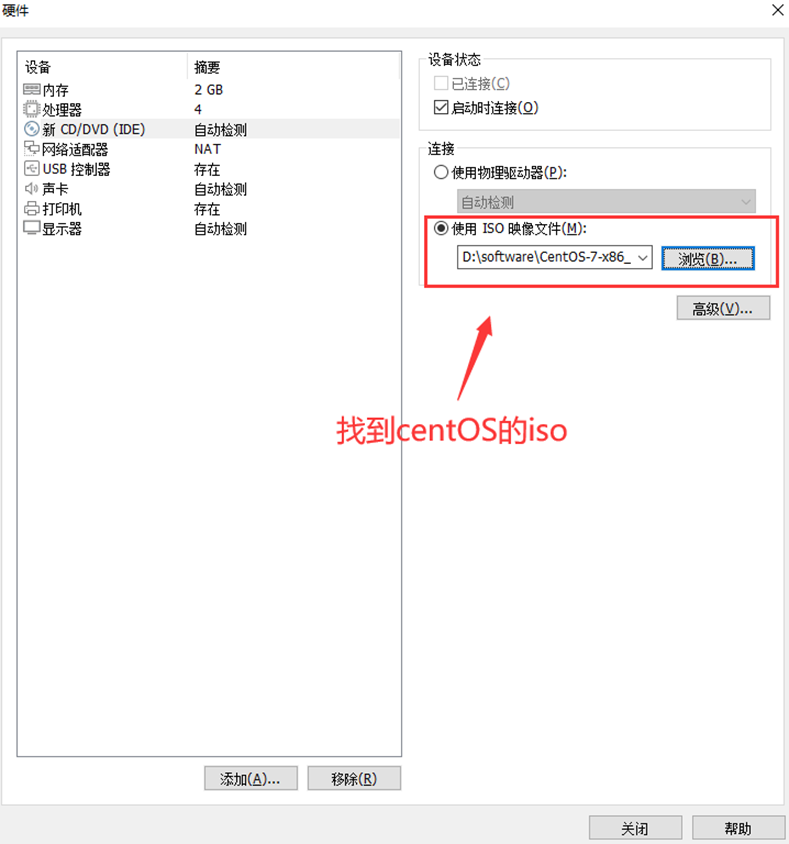
1、新建虚拟机 → 选择自定义
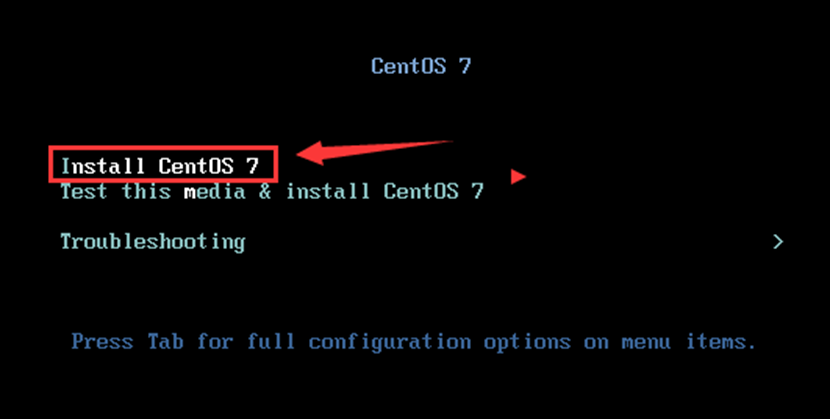
2、安装虚拟机
3、
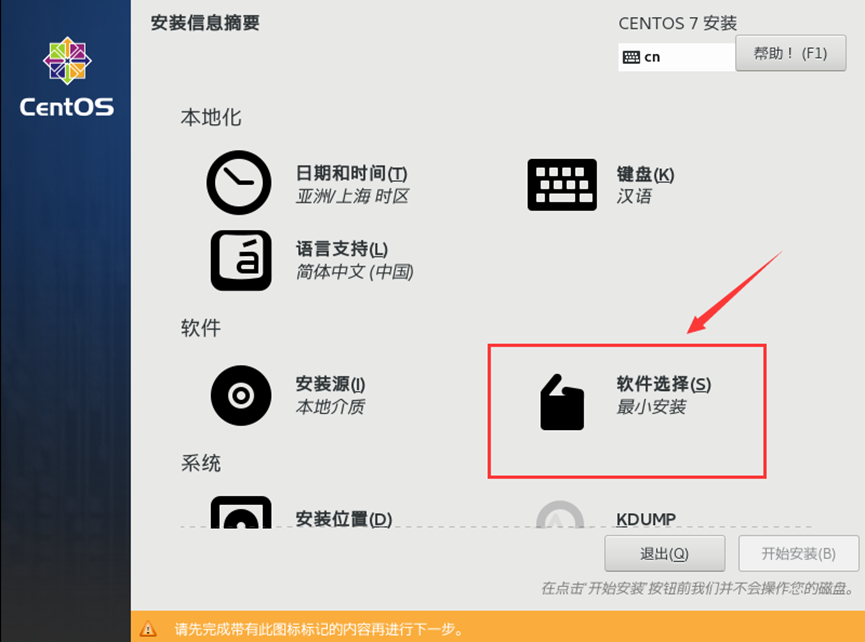
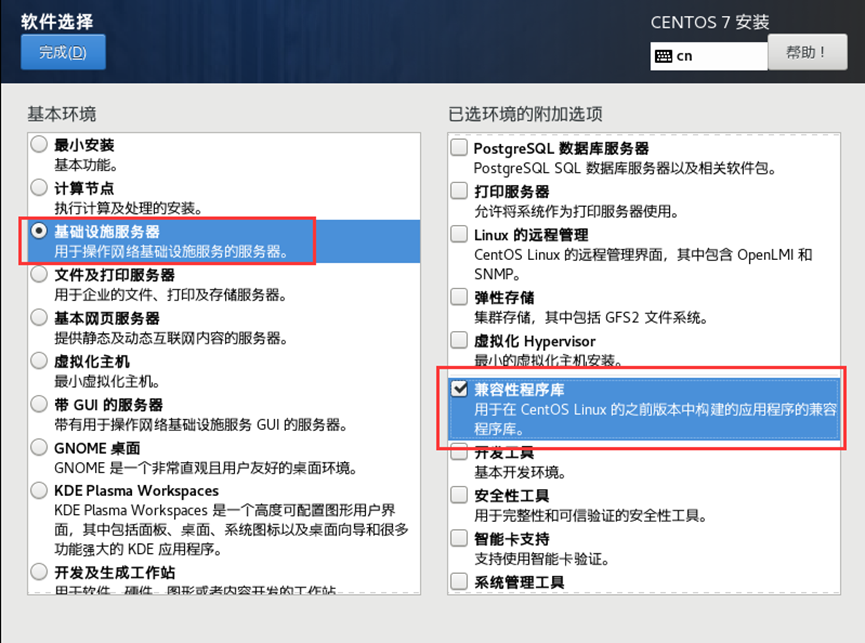
4、
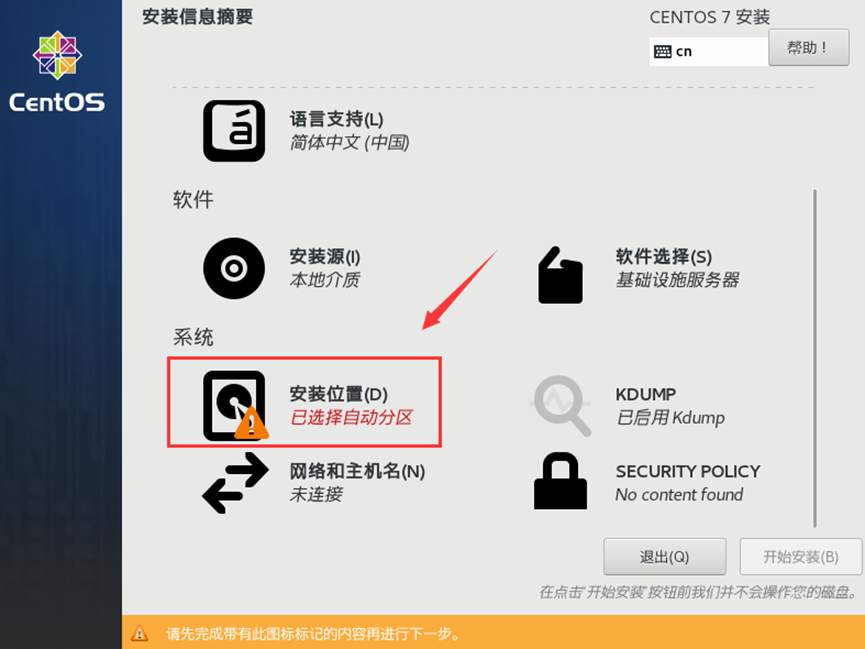
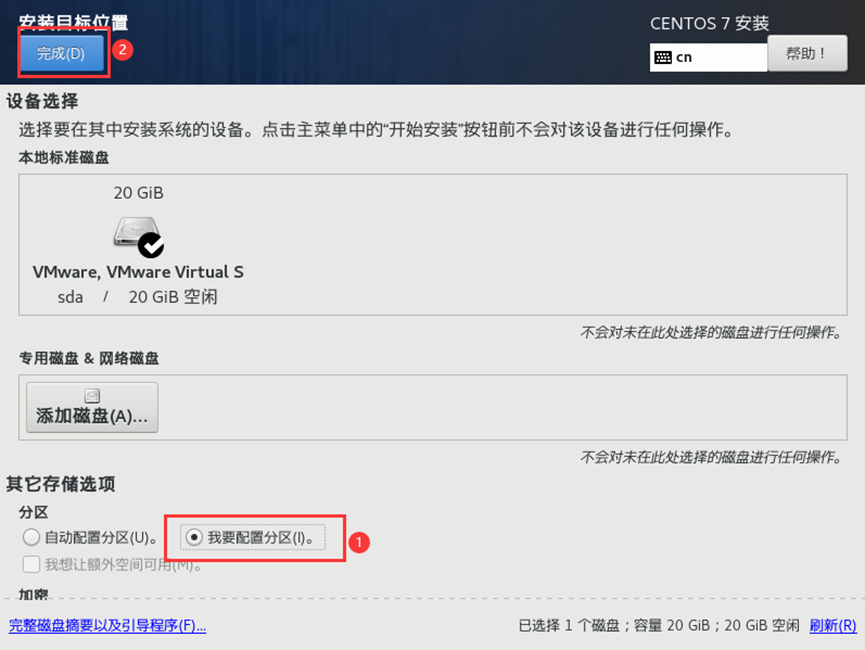
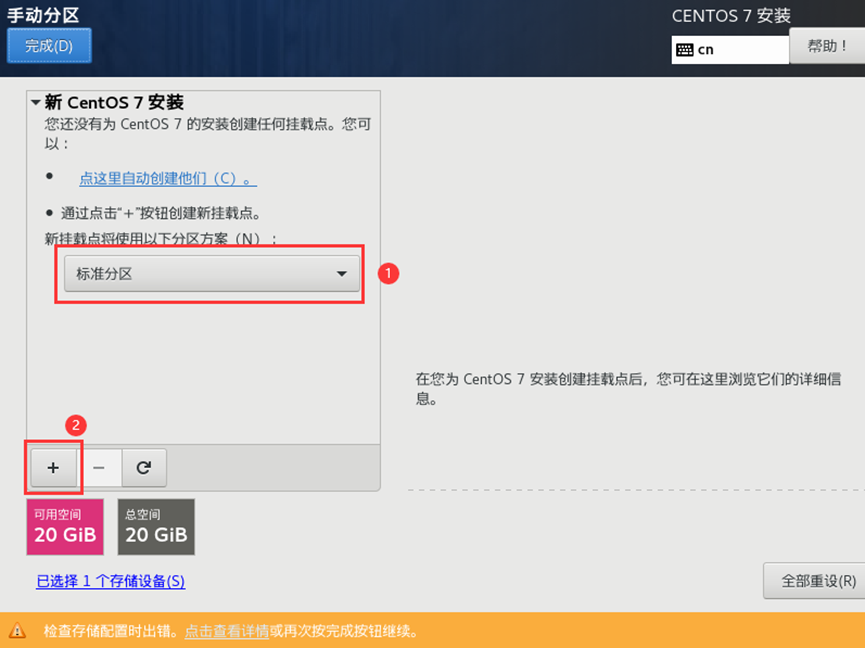
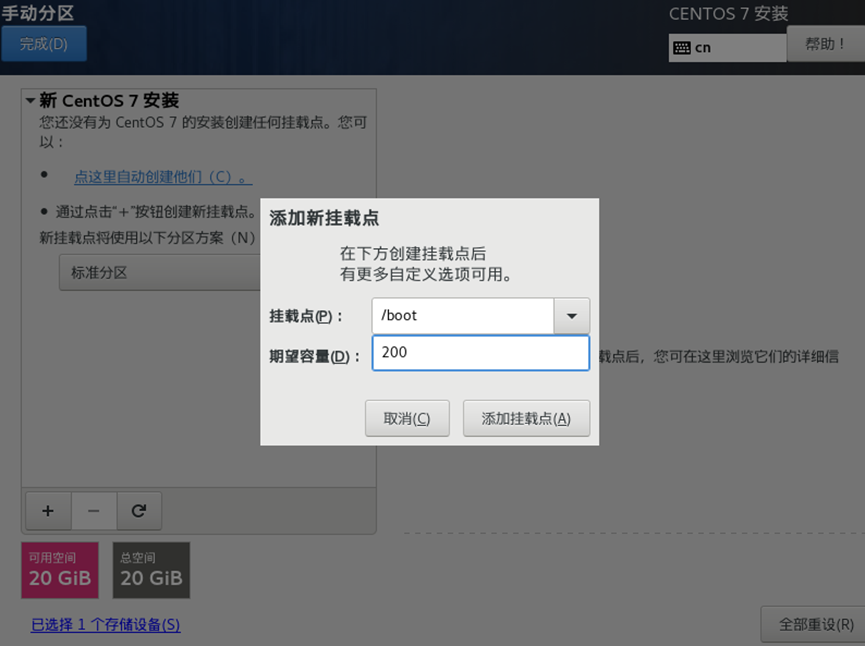

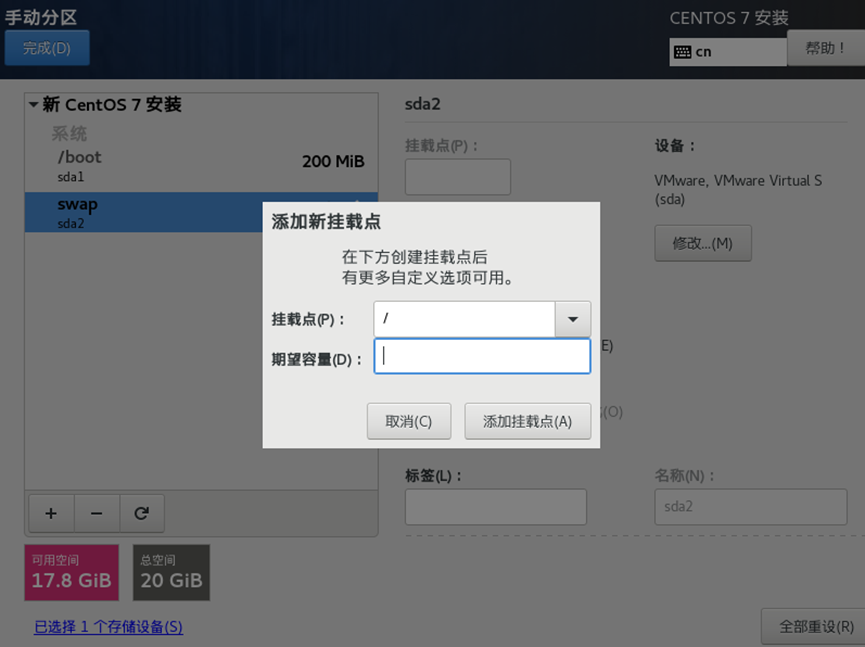
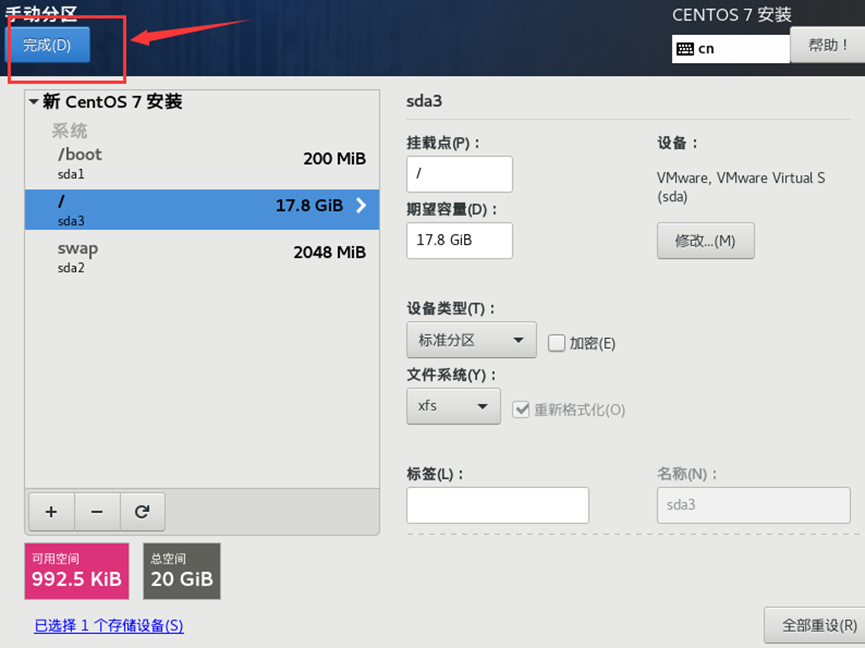
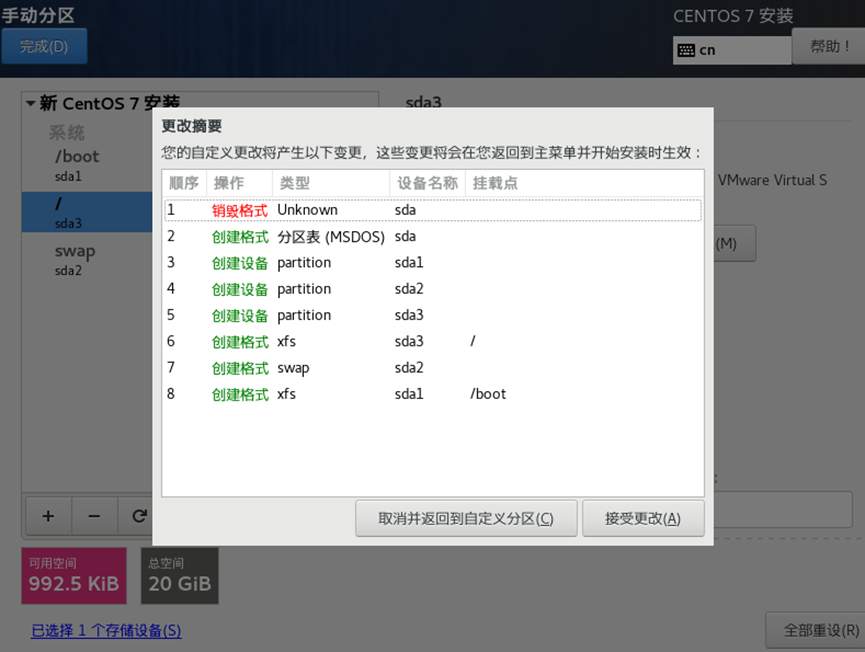
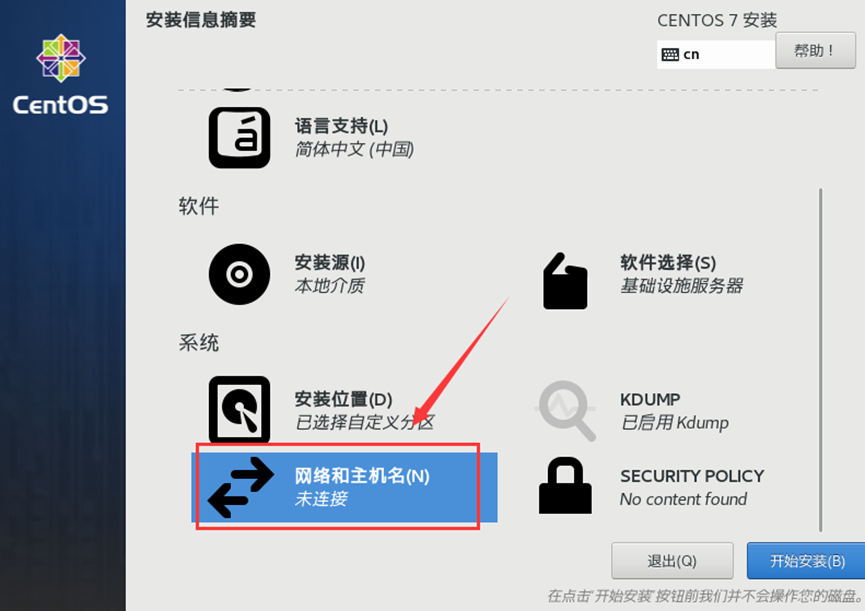
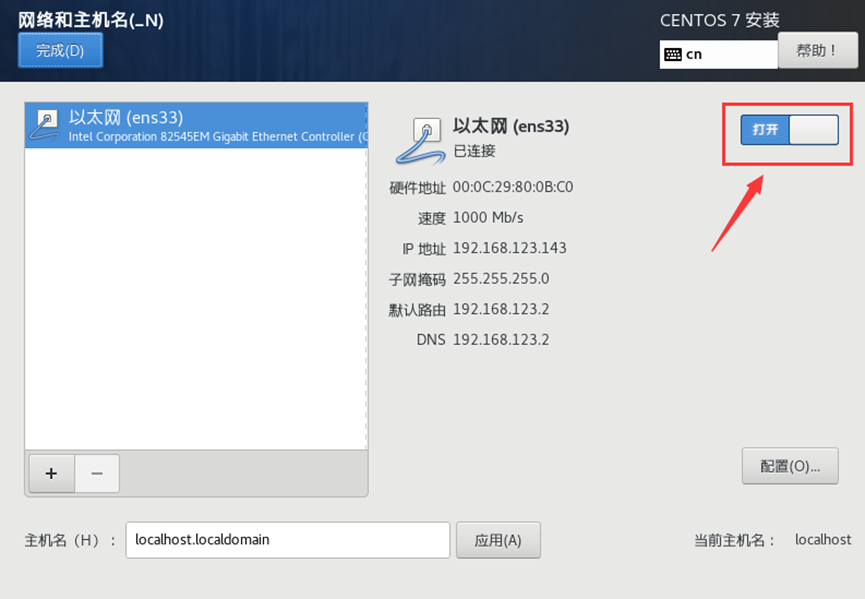
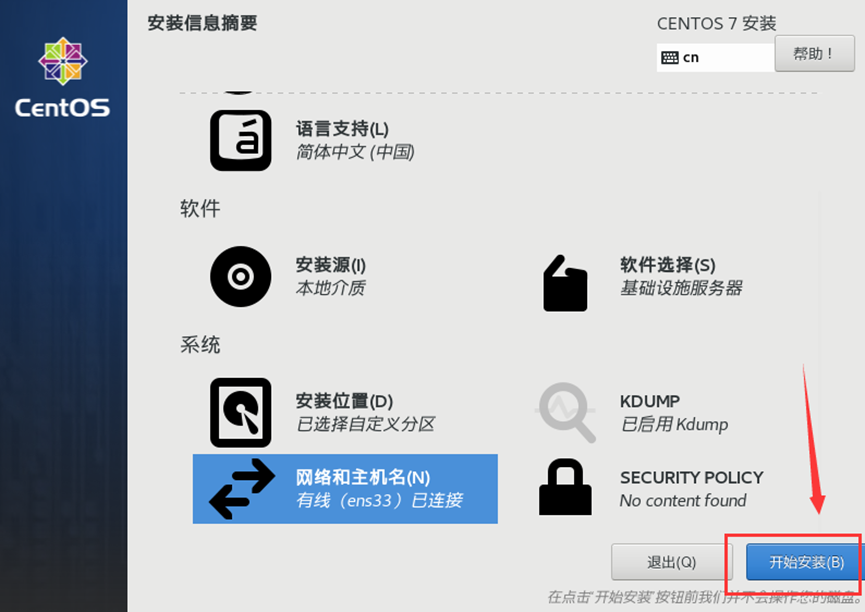
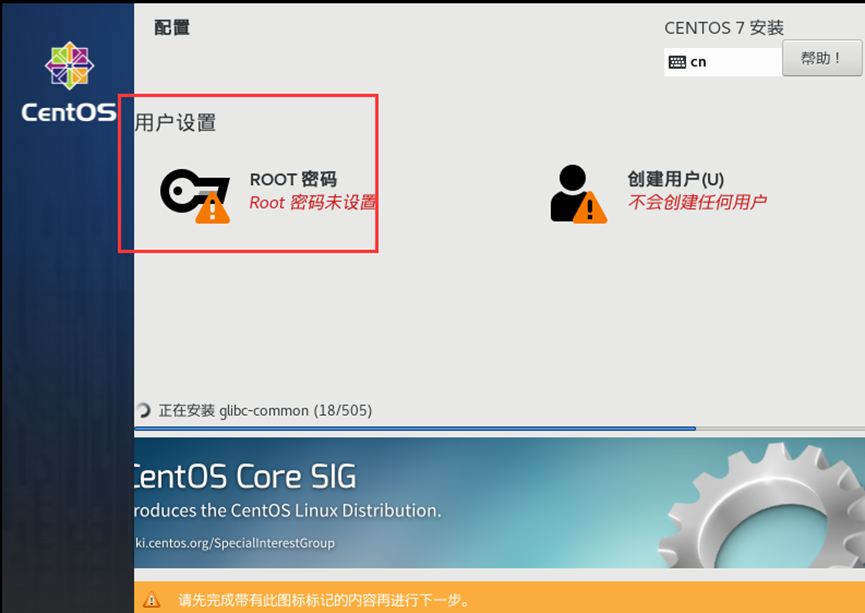
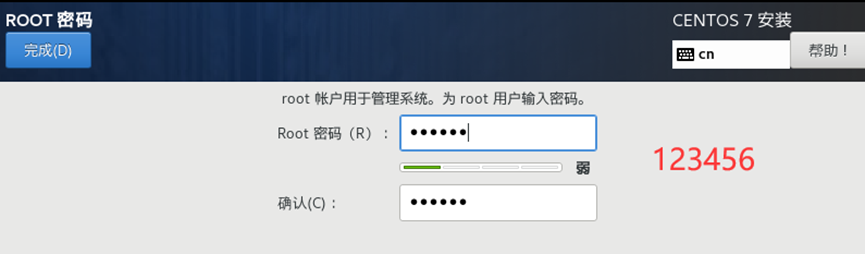
需求2:虚拟机初始化
登录虚拟机
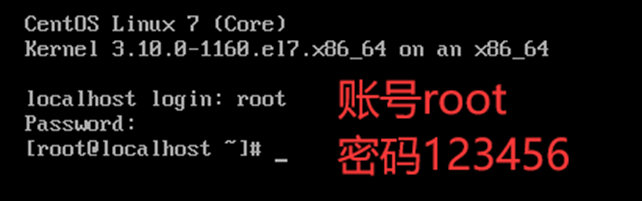
主机名、hosts文件、静态IP地址配置、关闭防火墙
主机名、hosts文件、静态IP地址配置、关闭防火墙
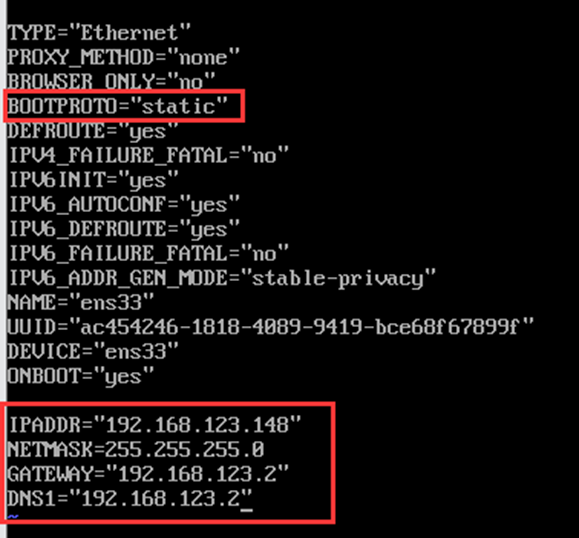
1、 静态IP地址配置
① 修改CentOS网卡配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33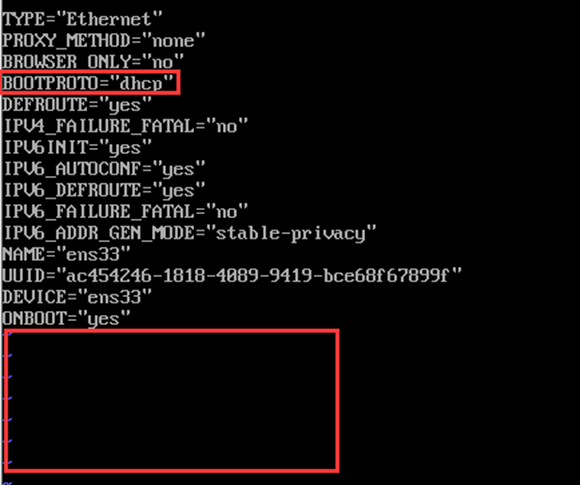
① 重启网卡
service network restart② 查看新ip是否生效
ifconfig③ 测试网络连接
ping [www.baidu.com](http://www.baidu.com)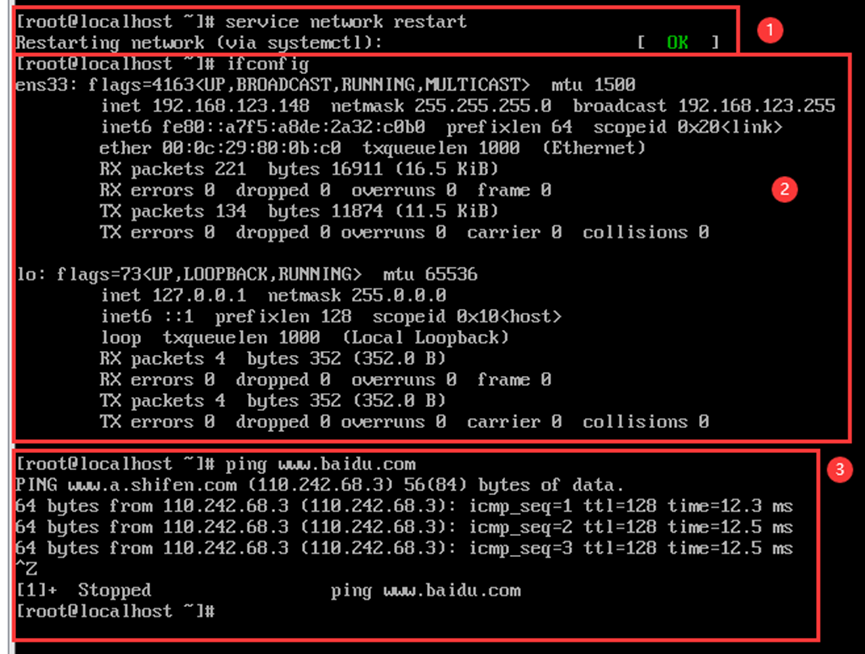
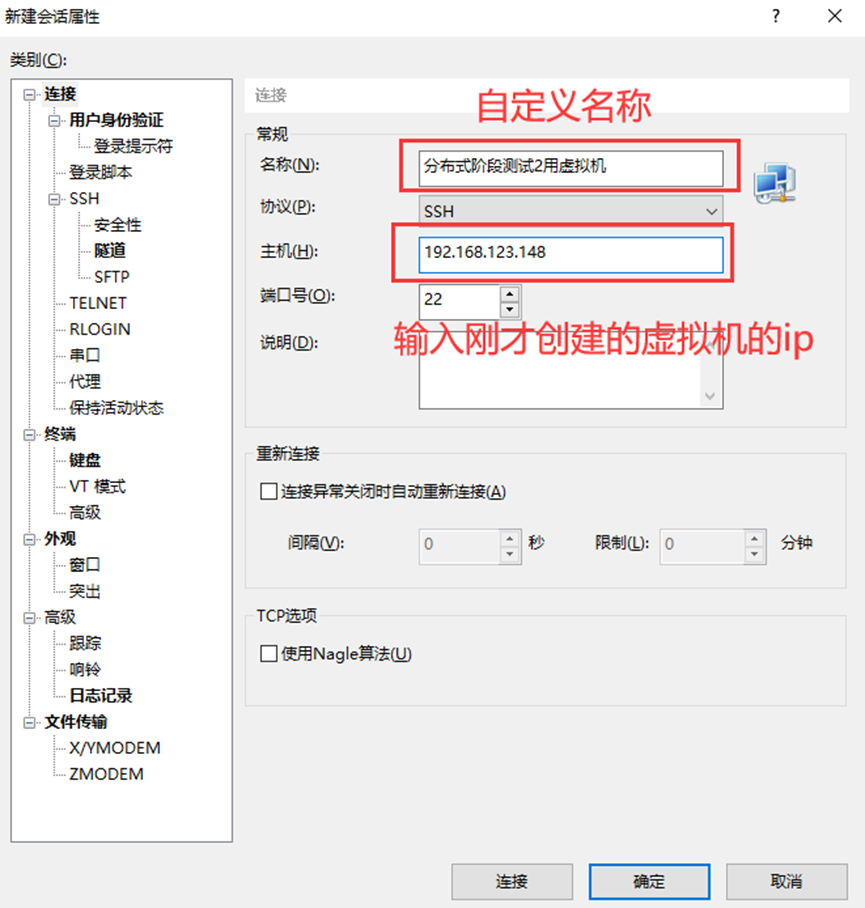
使用Xshell连接此虚拟机

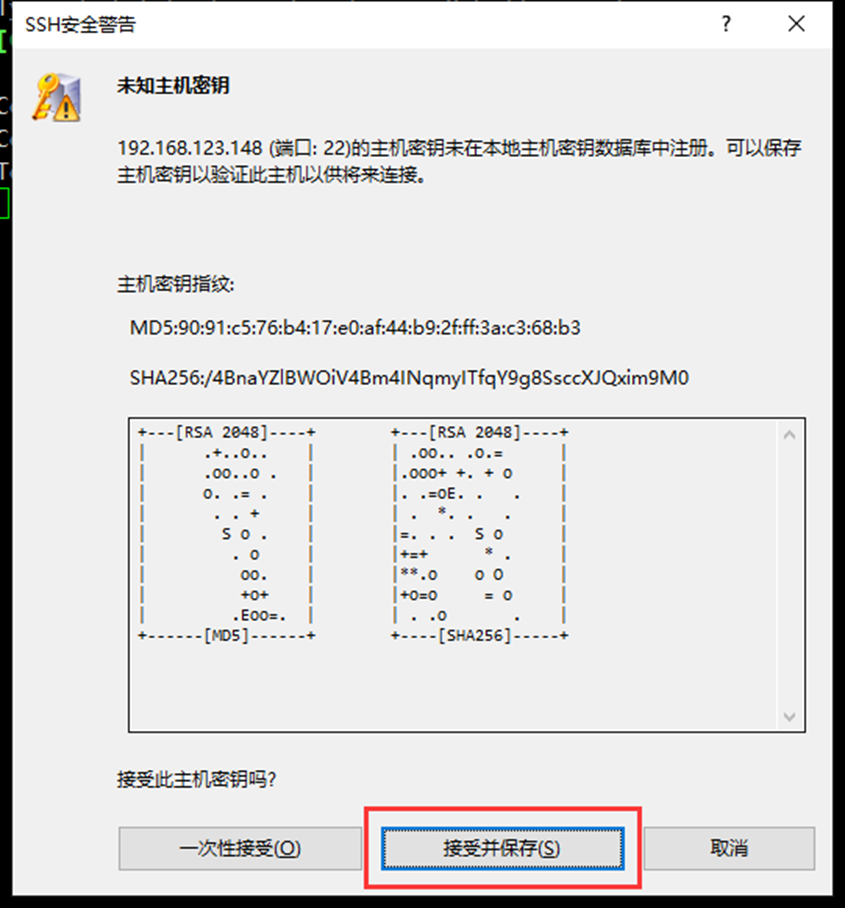

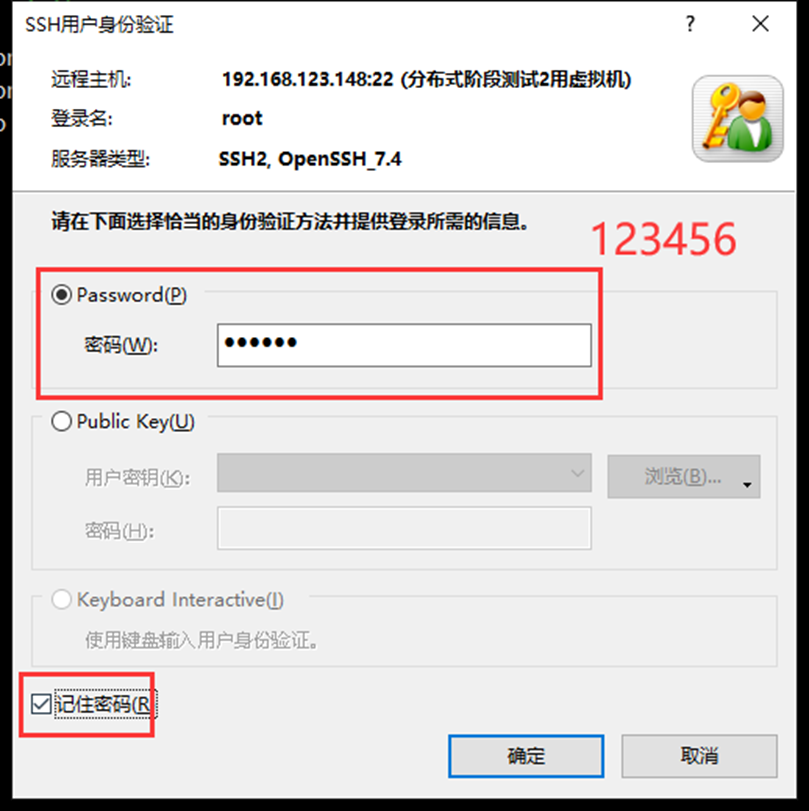
2、 主机名修改(将主机名设为hadoop01)
hostnamectl set-hostname hadoop01(在Xshell中需要重新连接才能刷新更改的主机名)
3、 host文件修改
vim /etc/hosts删除文件所有内容,添加如下内容
192.168.123.148 hadoop014、 关闭防火墙
查看防火墙状态:
firewall-cmd –-state关闭防火墙:
systemctl stop firewalld.service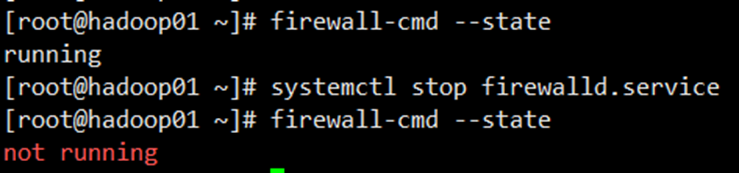
需求3:安装JDK,Hadoop软件,并配置好环境变量
1、文件上传至虚拟机
在opt目录下创建software目录:mkdir /opt/software
跳转至该目录
这里安装一个可直接拖拽传输文件的插件:yum install lrzsz
把文件从本地中拖拽至该虚拟机software目录下
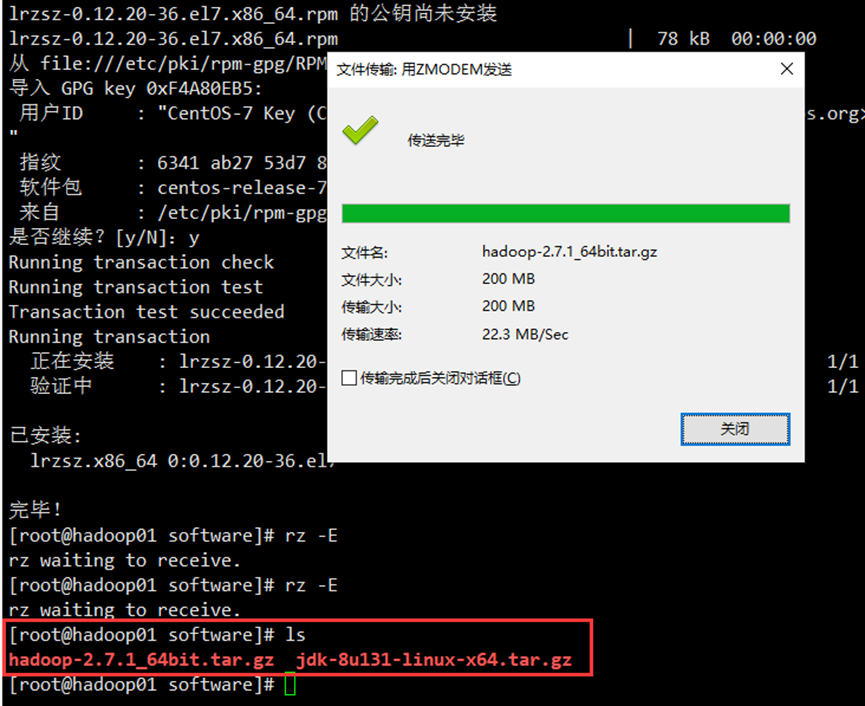
2、安装JDK,Hadoop软件,并配置好环境变量
a. 解压JDK和Hadoop
tar -xvf jdk-8u131-linux-x64.tar.gz
tar -xvf hadoop-2.7.1_64bit.tar.gzb. 打开Linux系统的环境配置变量:vim /etc/profile
在文件的最下方新增内容
export JAVA_HOME=/opt/software/jdk1.8.0_131
export HADOOP_HOME=/opt/software/hadoop-2.7.1
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH刷新环境变量:source /etc/profile
需求6:编写Hadoop的配置文件
跳转至Hadoop根目录:cd $HADOOP_HOME/etc/hadoop
修改hadoop-env.sh文件的25行和33行
第25行

修改为↓
export JAVA_HOME=/opt/software/jdk1.8.0_131第33行

修改为↓
export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.1/etc/hadoop修改core-site.xml文件
在<configuration> </configuration>中间添加如下内容
<!--用来指定HDFS的Leader-namenode的地址-->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!--用来表明hadoop运行时所产生的文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>修改hdfs-site.xml文件
在<configuration> </configuration>中间添加如下内容
<!--指定HDFS保存的副本数量,包括自己的节点,默认的值是3,但由于目前配置的伪分布,所以1即可-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上进行操作-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>修改mapred-site.xml文件
由于此文件不存在,需要通过cp方式获取:cp mapred-site.xml.template mapred-site.xml
在<configuration> </configuration>中间添加如下内容
<!--指定MapReduce运行在Yarn上面-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>修改yarn-site.xml文件
在<configuration> </configuration>中间添加如下内容
<!--指定Yarn的Boss,ResourceManager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- NodeManager获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>修改slaves文件
删除全部内容,添加如下内容
hadoop01需求4:使用RSA非对称加密算法创建免密证书
生成证书:
ssh-keygen后面直接回车
需求 5:虚拟服务器可实现免密访问
将公钥证书文件发送给需要免密登录的服务器(这里发给自己)
ssh-copy-id hadoop01有要输入密码的提示就输入:123456
免登录检测
ssh hadoop01如果不需要密码则成功
exit退出登录
需求7:启动分布式系统
启动hadoop伪分布式
1、格式化Hadoop的Namenode节点:
hadoop namenode -format2、启动Hadoop:
start-all.sh3、输入jps查看进程是否完整(若有如下5个进程则成功)
DataNode
Jps
SecondaryNameNode
NodeManager
ResourceManager4、访问Hadoop
确保防火墙关闭
在本地浏览器访问如下地址
若出现下图则表示Hadoop伪分布式配置+启动成功
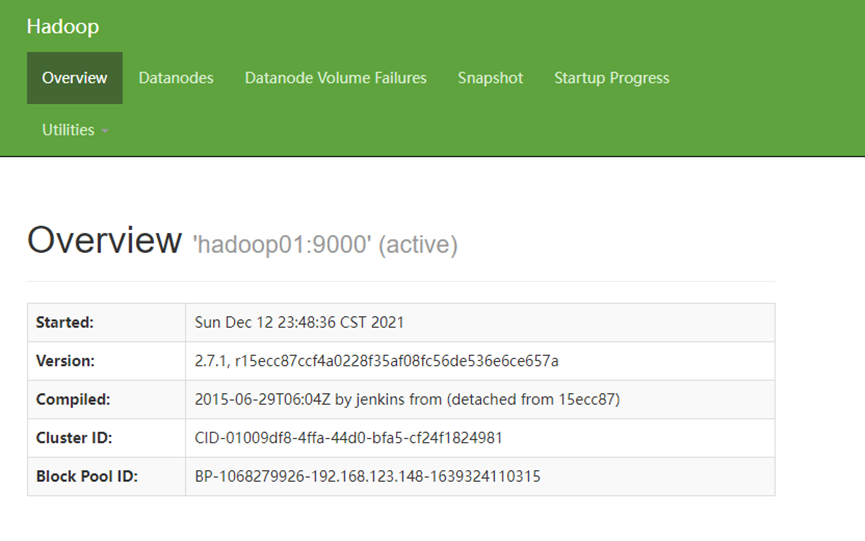
需求8:hive
启动Hive,并能够成功创建Hive库和stu外部表管理HDFS上的数据
将文件apache-hive-1.2.2-bin.tar.gz放到虚拟机software目录下
解压:
tar -xvf apache-hive-1.2.2-bin.tar.gz修改目录名为hive-1.2.2:mv apache-hive-1.2.2-bin hive-1.2.2
启动hive:
./hive创建数据库hive:
hive> create database hive;在Eclipse中
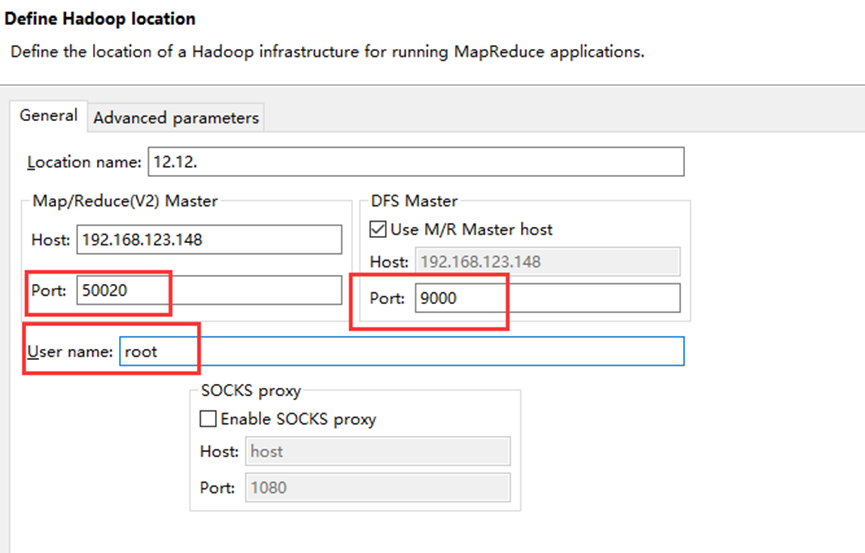
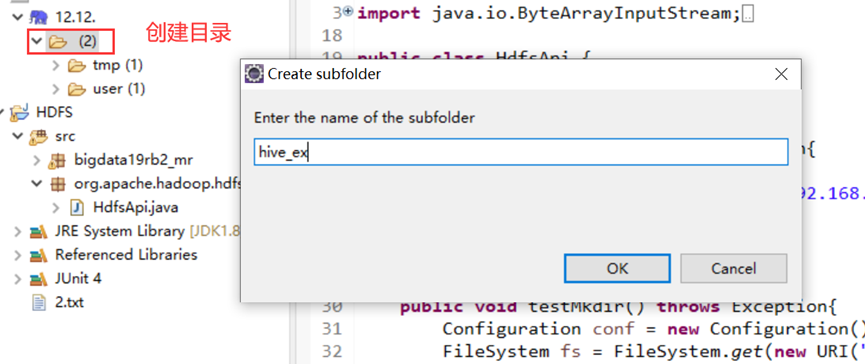
在hive_ex目录上传stu.txt文件
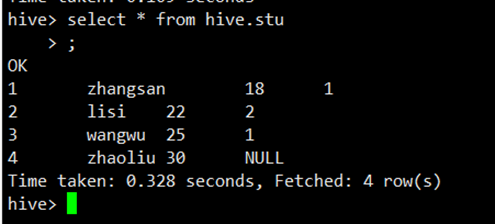
stu.txt文件内容如下
1 zhangsan 18 1
2 lisi 22 2
3 wangwu 25 1
4 zhaoliu 30在hive中创建外部表
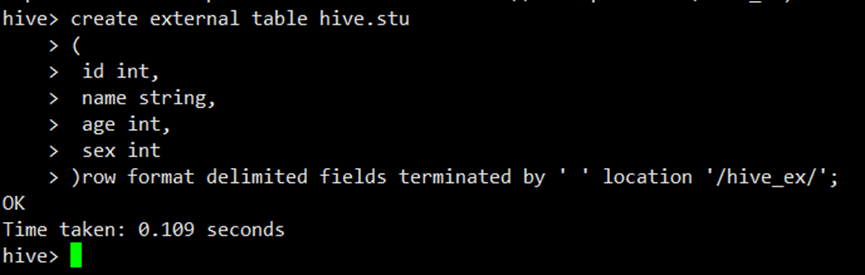
create external table hive.stu
(
id int,
name string,
age int,
sex int
)row format delimited fields terminated by ' ' location '/hive_ex/';